개인적으로 PBS(Proxmox Backup Server)를 PVE Cluster내 VM으로 운영하고 PBS VM Storage를 NFS에 연결하여 사용하며 HA 구성하여 사용한다.
운용중인 VM은 Disk 성능 상의 이유로 Local Disk를 사용하며 PBS로 주기적으로 백업 하고 있다.
PBS VM 이 있는 Node가 장애가 발생 할 경우 HA Migrate를 용이하게 하며 Disk 성능을 크게 탈 필요가 없다. (1G UTP 기준 NFS 성능은 1G 순차 쓰기에 100MB/s 미만의 성능을 보여 준다.)
PBS HA를 하지 않는 경우는 참조 : https://ploz.tistory.com/entry/proxmox-%EC%84%9C%EB%A1%9C-%EB%8B%A4%EB%A5%B8-PBSProxmox-Backup-Server-%EC%97%90-DataStore-%EA%B3%B5%EC%9C%A0-%ED%95%98%EA%B8%B0
[proxmox] 서로 다른 PBS(Proxmox Backup Server) 에 DataStore 공유 하기
DataStore를 공유(Local Disk가 아닌 NFS 등을 사용)하는 경우의 수는 여러가지가 있겠지만 개인적인 이유는 아래 2가지 이다. 1개의 DataStore를 공유하는 다수의 PBS를 운영 하고자 경우 운영중이던 PBS에
ploz.tistory.com
요구사항
Proxmox VM의 HA 구성을 위하여 proxmox 에서 권장하는 요구 사항이 있다.
- at least three cluster nodes (to get reliable quorum)
- quorum(정족수) 를 채우기 위한 3개 이상의 pve node
- vm 혹은 node 가 실패했을경우 확정적인 실패로 간주하기 위해 3개이상의 정족수가 필요
- shared storage for VMs and containers
- VM Storage는 Local Storage가 아닌 외부 Shared 한 Storage(NFS 등)를 이용
- Local Storage를 사용한 VM은 HA 동작이 실패 한다.
- hardware redundancy (everywhere)
- 파워나 Disk Raid 등 하드웨어 이중화
- use reliable “server” components
- hardware watchdog - if not available we fall back to the linux kernel software watchdog (softdog)
- watchdog 을 이용하여 시스템이나 하드웨어의 이상시 재기동 할 수 있다.
- 기본적으로 보안상의 이유로 하드웨어 watchdog module은 block 되어 있다.
- optional 로 취급가능
- optional hardware fencing devices
설정
HA Node Status
3개 이상의 Node 의 상태정보
CLI
- ha-manager status : Node 정보 및 HA 구성 된 VM 정보 표출
$ ha-manager status
quorum OK
master TEST03 (active, Tue Jul 4 17:15:16 2023)
lrm TEST03 (idle, Tue Jul 4 17:15:19 2023)
lrm TEST01 (idle, Tue Jul 4 17:15:23 2023)
lrm TEST02 (idle, Tue Jul 4 17:15:18 2023)
lrm TEST04 (idle, Tue Jul 4 17:15:23 2023)
service vm:143 (TESt04, queued)
GUI
- 경로 : Datacenter - HA

HA GROUP 구성
HA로 구성할 Node를 선택하고 우선수위를 설정 할 수 있다.
- GUI 경로 : Datacenter - HA - Groups
HA를 구성할 VM에 Group을 설정할 수 있다.
- HA에 참여할 Node를 선택할 수 있다.
- 선택한 Node에 우선순위(Priority) 를 설정 할 수 있다.
- 우선순위가 높은 Node에 우선 할당 된다.
- 운용 중인 VM 에 HA를 구성 Group을 설정하면 Fail 되지 않은 VM 이라도 우선순위에 적용을 받아 Migrate 된다.
- nofailback : 우선순위가 높은 Node에 있던 VM 이 Fail 되어 Migrate 되었을 경우 우선순위가 높은 Node가 살아나더라도 failback 되지 않는다.
- restricted : 특정 Node에서만 운영되도록 VM 을 설정한다. Node(restricted Node)가 Fail 되어 Migrate될 경우 Node(restricted Node)가 다시 살아나면 restricted Node 로 다시 Migrate 된다.
HA 구성
VM 별로 HA 설정이 가능하다.
- GUI 경로 : Datacenter - HA - Add 혹은 각 VM - More - Manage HA
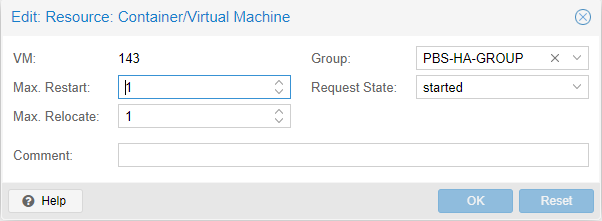
- Max. Restart : Started 에 실패 할 경우 VM 재시작 시도 횟수
- Max. Relocate : Node로 재배치가 실패 할 경우 재배치 시도 횟수로 Max. Restart 후에 발생한다.
- Group : 설정할 그룹
- Request State : CRM(Cluster Resource Manager) 이 유지하고자 하는 VM의 상태 정보.
- started : VM이 started 상태를 유지하기위해 노력한다. Stopped 상태 일경우 started 하려고 시도 하며 실패할 경우 Max. Restart 후에 Max. Relocate를 시도한다. 모든 과정이 실패하면 error 상태가 된다.
- stopped : VM이 stopeed 상태를 유지하기위해 노력한다. 하지만 Node가 Fail 일 경우는 Max. Relocate를 수행한다.
- disabled : VM이 stopeed 상태를 유지하기위해 노력하며 Fail 한 Node 에서 Max. Relocate 하려고 시도하지 않는다.
- ignored : CRM, LRM(Local Resource Manager) 가 아무것도 하지 않는다. API 명령을 비롯 Fail 한 Node 에서 Max. Relocate 하려고 시도하지 않는다.
'가상화 > Proxmox' 카테고리의 다른 글
| [proxmox] HA Fencing (softdog을 이용한 node reboot) (0) | 2023.09.26 |
|---|---|
| [proxmox] Cloud-init Template으로 배포하기 (0) | 2023.09.06 |
| [proxmox] 서로 다른 PBS(Proxmox Backup Server) 에 DataStore 공유 하기 (0) | 2023.06.30 |
| [proxmox] qemu guest agent 설치하기 (0) | 2023.06.26 |
| [proxmox] CentOS7 Template 만들기(수동, 자동) (3) | 2023.05.10 |


