관련글은 아래 링크를 참조 하도록 한다.
- elasticsearch 단일 node에 8.14.x 설치하기(SSL 포함)
- elasticsearch cluster 구축하기
- elasticsearch cluster에 kibana 붙이기(SSL 포함)
- elasticsearch cluster에 logstash 붙이기(SSL 포함)
- elasticsearch ILM 적용을 통한 Hot-Warm-Cold 아키텍쳐 구현해 보기[1]
- elasticsearch ILM 적용을 통한 Hot-Warm-Cold 아키텍쳐 구현해 보기[2]
- elasticsearch Data Stream에 ILM 적용시켜보기
ILM 정책 설정
ILM 정책은 Hot, Warm, Cold, Delete의 4가지 단계로 나뉜다. 각 단계 별로 진입 시점과 인덱스 관리에 대한 설정을 정의하며 정책은 순서대로 진행된다. 몰론 정의 되지 않은 단계는 제외 된다.
빠른 테스트를 위해 Hot, Warm 단계만 설정하고 단계별 진입 시간을 분단위로 설정한다.
"test-ilm" 이라는 이름의 ILM 정책을 만들것이다. API를 사용해도 되며 Kibana 에서 진행해도 된다.
Kibana
경로 : Menu - Management - Stack Management - Index Lifecycle Policies - Create policy
Hot phase
- index가 생성되고 최소 1개의 document가 인덱싱되면 설정에 따라 3분뒤에 rollover 된다.
- Index Priority 는 노드가 재시작 될때 혹은 유실되었을때 복원해야할 우선순위를 설정하는 것으로 Hot > Warm > Cold 순으로 높게 설정해야 한다.
Warm Phase
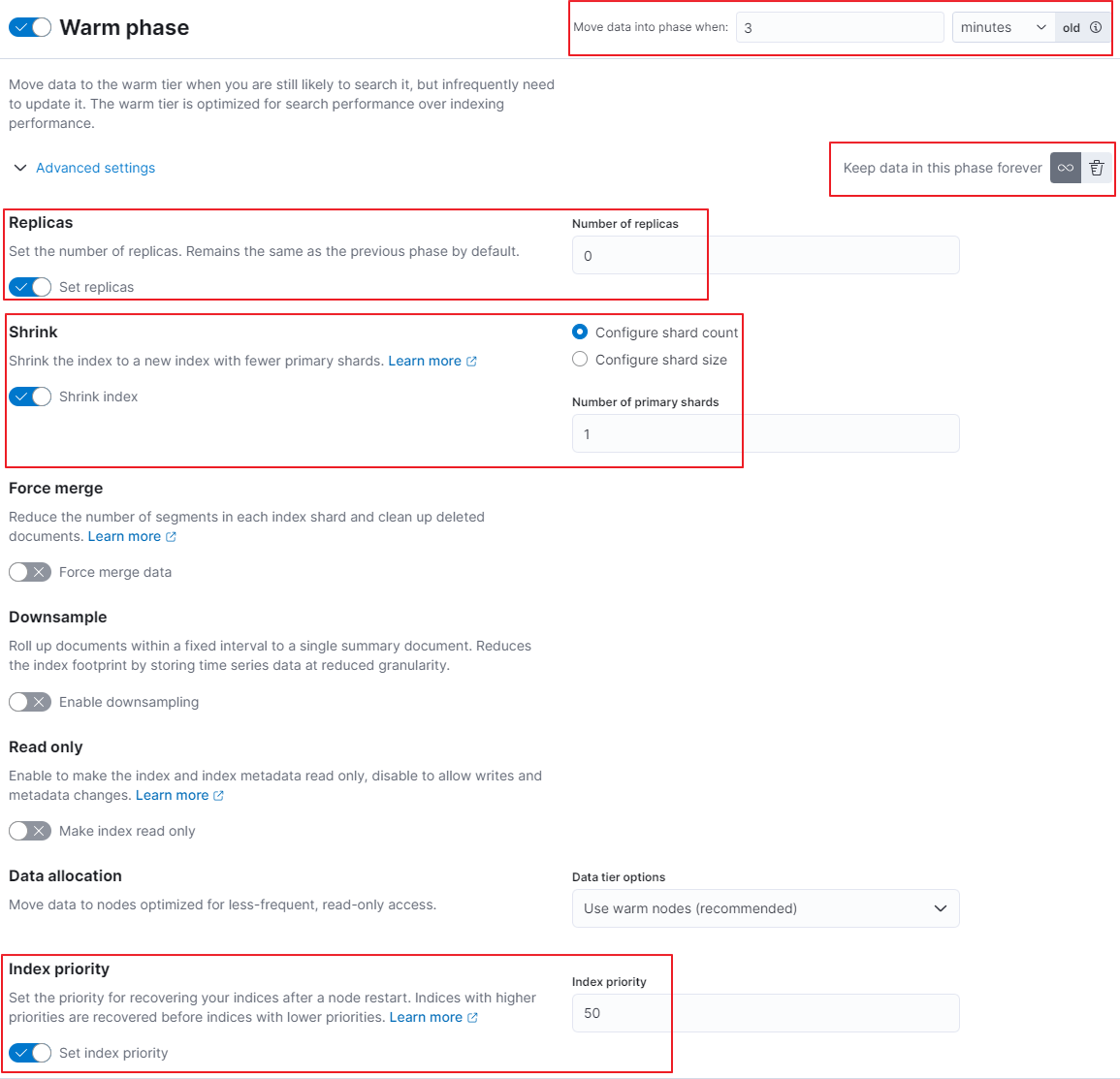
- Hot Phase에서 roll over 후 설정( Move data into phase when)에 따라 3분이 지나면 Warm Phase에 진입한다.
- 3분이 지나도 WarmPhase에 진입하지 않고 약 10분정도 있다가 진입하는 경우도 있는데 이는 ILM Cluster Level Setting 때문이다.
- indices.lifecycle.poll_interval : (default 10m) ILM 정책을 충족하는 인덱스를 검색하는 주기로 기본값은 10분이다. 아래와 같이 변경한다.
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "5s"
}
}indices.lifecycle.history_index_enabled : (default true) ILM 정책이 수행된 작업의 기록을 인덱스(ilm-history-*)에 기록한다.
indices.lifecycle.rollover.only_if_has_documents : (default true) 최소한 하나의 문서가 포함된 인덱스만 롤오버한다.
참조 : https://www.elastic.co/guide/en/elasticsearch/reference/current/ilm-settings.html
- Data allocation : data_warm 노드로 index migrate.
- Replicas : migrate되는 index의 replica는 0개로 설정.
- Shrink : migrate 된 index의 shard 개수를 1개로 축소.
- Force merge : index의 세그먼트수를 줄인다. index의 세그먼트 수 확인은 다음과 같다.
GET my-index/_segments
API
PUT _ilm/policy/test-ilm
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
},
"rollover": {
"max_age": "3m"
}
}
},
"warm": {
"min_age": "3m",
"actions": {
"set_priority": {
"priority": 50
},
"shrink": {
"number_of_shards": 1,
"allow_write_after_shrink": false
},
"allocate": {
"number_of_replicas": 0
}
}
}
}
}
}
Index Template
Index Template을 생성하지 않고 Logstash에 수집할때 Output 설정에 ilm을 위에 생성한 "test-ilm"을 지정만 해도 Index Template은 자동으로 생성된다.
elasticsearch {
hosts => "ES_IP:9200"
user => "elastic"
password => "[패스워드]"
ilm_enabled => true
ilm_rollover_alias => "cf-http-log"
ilm_pattern => "000001"
ilm_policy => "test-ilm"
}이후 추가적으로 shard 수나 replica 설정 그리고 index의 라우팅 설정등을 생성된 Index Template에 추가적으로 해주어야한다. ILM 정책을 Hot Phase와 Delete 정책만을 가져간다면 Logstash에서만 설정해도 가능하다는 이야기 이니 참고만하면 될거 같다.
Index Template 생성
"cf-http-log-tmpl" 이라는 이름으로 template을 생성 한다.
Kibana, API 둘다 설정 가능하지만 여기는 API로만 설정한다.
- number_of_shards : index의 shard 수는 2개로 설정
- number_of_replicas : index의 replica 수는 1개로 설정
- ndex.lifecycle.name : index에 적용할 ilm 정책
- index.lifecycle.rollover_alias : rollover alias 설정. 실제 index에서도 동일한 alias가 설정되어야한다.
- index.routing.allocation.include._tier_preference : data_hot node에 index 생성.
- tier_preference 는 data_cold, data_warm, data_hot 순으로 생성가능한 node를 검색하고 있다면 할당한다.
- 즉 data_cold node가 있으면 할당하고 없으면 data_warm 노드가 있는지 검색한다. data_warm 노드가 있다면 할당하고 없으면 data_hot 노드로 넘어가게 된다.
- 데이터 스트림의 경우 인덱스 생성시 자동으로 " index.routing.allocation.include._tier_preference: data_hot" 설정이 추가 된다.
- 일반적인 인덱스 생성시 에는 자동으로"index.routing.allocation.include._tier_preference: data_content" 설정이 추가된다.
참조 : https://www.elastic.co/guide/en/elasticsearch/reference/current/data-tier-shard-filtering.html#data-tier-allocation-filters
PUT _index_template/cf-http-log-tmpl
{
"index_patterns": ["cf-http-log-*"],
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"index.lifecycle.name": "test-ilm",
"index.lifecycle.rollover_alias": "cf-http-log",
"index.routing.allocation.include._tier_preference": "data_hot"
}
}
}
Index 생성
Logstash에서 데이터를 밀어넣을 index를 미리 생성한다. 이때 index.lifecycle.rollover_alias 에서 설정한 값과 동일한 값을 설정해야한다. 그리고 index 이름은 rollover가 될 수 있게 pattern을 미리 입력한다.(cf-http-log-2024-08-05-000001)
PUT cf-http-log-2024-08-05-000001
{
"aliases": {
"cf-http-log": {
"is_write_index": true
}
}
}
Logstash 설정
Logstash Output 설정을 통해 데이터를 수집한다. index 이름은 pattern을 제외한 이름을 입력한다. rollover alias 과 동일하게 가져가는 것이 좋다.
elasticsearch {
hosts => ["http://test-ES01:9200","http://test-ES02:9200","http://test-ES03:9200"]
user => "logstash_writer"
password => "[패스워드]"
index => "cf-http-log"
}
ILM 진입 확인
elasticsearch head tool을 이용하여 아래 그림과 같이 ilm 단계를 진입할 때 상황을 나타낸것이다.
물론 ilm-history-* 를 살펴보면 여러 단계를 거치게 되지만 위 설정을 기반으로 해서 크게 볼수 있는 내용만 나타낸 것이다.
data_hot : es-node01, es-node02
data_warm : es-node03, es-node04
Hot Phase : 1개 이상의 document를 가진 index는 3분후 rollover 된다.
Warm Phase : rollover 되고 3분 후 Warm Phase에 진입하며 data_warm node로 migrate되며 replica는 0개, primary shard 는 1개로 축소 된다.
- 1 : 현재 활성화 된 Index로 2개의 primary, 2개의 replica shard를 가지고 있다.
- 2 : Hot Phase의 rollover 정책에 따라 rollover 된 index로 2개의 primary, 2개의 replica shard를 가지고 있다.
- 3. Warm Phase의 migrate 정책에 따라 data_warm node로 migrate 되었으며 이때 migrate되면서 replica를 0개가 된다.
- 4. : Warm Phase의 Shrink 정책에 따라 Primary shard는 1개로 축소된다.

Elasticsearch Head 는 크롬 확장 프로그램에서 검색할 수 있고 설치 후 사용한다.
'Monitoring Tools > ELK Stack' 카테고리의 다른 글
| [elasticsearch] Data Stream에 ILM(Index Lifecycle Management) 적용시켜 보기 (0) | 2024.08.07 |
|---|---|
| [elasticsearch] ILM(Index Lifecycle Management) 적용을 통한 Hot-Warm-Cold 아키텍쳐 구현해 보기 [1] (0) | 2024.08.06 |
| [logstash] elasticsearch cluster에 logstash 붙여보기(SSL 포함) (0) | 2024.07.26 |
| [kibana] elasticsearch cluster에 kibana 붙이기 (0) | 2024.07.24 |
| [elasticsearch] cluster 구축하기(8.14.x, CentOS, xpack security) (2) | 2024.07.24 |

